Préparer son écran
Pour cet exemple nous allons choisir la facilité, l'écran carré!
Il présente la propriété remarquable de reboucler absolument sans effort. Si on utilise une texture cyclique, on peut faire un scrolling infini en changeant la programmation du CRTC/ASIC sans changer le moindre octet à l'écran.
ld bc,#BC01 : out (c),c : ld bc,#BD20 : out (c),c ; 32 word width
ld bc,#BC02 : out (c),c : ld bc,#BD00+43 : out (c),c
ld bc,#BC06 : out (c),c : ld bc,#BD20 : out (c),c ; 32 block height
ld bc,#BC07 : out (c),c : ld bc,#BD22 : out (c),c ; vertical position
ld bc,#BC00+12 : out (c),c : ld bc,#BD20 : out (c),c
ld bc,#BC00+13 : out (c),c : ld bc,#BD00 : out (c),c
Et on se prend une jolie texture :)

Préparer ses ruptures
Voici un snipet de code que j'ai utilisé sous diverses formes dans la démo CRTC-3.
Comme on l'a vu dans le premier article de cette série, à chaque ligne que l'on souhaite voir afficher correspond une adresse principale et un numéro de bloc.
Et selon la ligne à laquelle on souhaite afficher ces informations, il faut compenser en accord avec le numéro de bloc courant réel du CRTC de l'ASIC.
Cette petite routine va calculer pour chaque ligne de notre texture, ses coordonnées CRTC+bloc. Notre texture fait la même taille que l'écran (256 lignes de haut et 64 octets de large).
Comme nous avons 256 lignes de textures, le stockage sera trivial, dans 3 tableaux de 256 octets, ce qui nous permettra de naviguer dans les données en changeant uniquement le poids fort.
preComputeASICinfo
; produire le tableau des adresses prémâchées CRTC/ASIC pour chacune des 256 lignes d'un écran carré de 64 de large
; SSR Block
; CRTC-13
; CRTC-12
ld ix,TABLE_SPLIT ; adresse de nos 3 tables, alignée sur 256 octets
ld hl,#C000 ; adresse de départ de nos données à afficher
ld c,32 ; nous avons 32 blocs de haut (de 8 lignes)
.computeASIClines
ld b,8 ; boucler sur les 8 lignes d'un bloc
.computeASIClinesBlock
push hl
ld a,h
add a
and #70
ld (ix+0),a ; valeur de bloc prémâchée pour le SSR
inc xh
srl h : rr l
ld a,l
ld (ix+0),a ; poids faible de l'adresse CRTC (REG13)
inc xh
; le calcul ci-dessous est compatible avec n'importe quelle adresse mémoire
; on découpe l'adresse pour renseigner les bits 0,1, 4 et 5 de l'équivalent CRTC registre 12
ld l,h
ld a,h
and #3
ld h,a
ld a,l
srl a
and #30
or h
ld (ix+0),a ; équivalent du REG12
dec xh : dec xh ; revenir sur le poids fort de départ de nos tables
inc xl ; passer à la ligne suivante dans les tables
pop hl
ld de,#800 ; aller à la ligne du dessous dans le bloc
add hl,de
djnz .computeASIClinesBlock
ld de,64-#4000 ; aller à la ligne du dessous en changeant de bloc
add hl,de
dec c ; encore un bloc à traiter?
jr nz,.computeASIClines
ret
Cette routine s'adapte facilement à toutes les largeurs/hauteurs d'écran. Le principe reste le même. Avoir pour chaque adresse un équivalent REG12/REG13 et SSR prémâché.
Gestion d'appel de plusieurs dizaines d'interruptions à la suite.
Pour réaliser notre rouleau, nous n'avons pas besoin de reprogrammer l'ASIC à chaque ligne* et nos sauts ou duplications de lignes auront toujours lieu au même endroit (car c'est la texture qui bouge, pas la déformation).
Pour minimiser l'empreinte CPU de ces routines, nous allons nous réserver les registres secondaires AF',BC',DE',HL', ainsi le changement de contexte ne se fera pas avec de coûteux PUSH/POP mais un simple EXX:EXA
À chaque interruption, nous avons besoin de :
- rapidement régler le SSR pour compenser le split-screen déclenchée en même temps que l'interruption.
- préparer le split-screen suivant.
- préparer l'interruption suivante.
Typiquement, pour sauter une ligne, nous aurons le code suivant (on s'en fait une macro)
macro splitSkip,combien
exx : exa ; permuter les registres AF,BC,DE,HL
ld a,compensation ; compensation de bloc en accord avec la ligne
compensation=compensation-#10*{combien} ; on ajoute autant de compensation qu'on avance
while compensation<0 : compensation+=#80 : wend ; cette boucle corrige la valeur pour qu'elle soit toujours entre #00 et #70
add (hl) : and #70 : ld (#6804),a ; ajouter au bloc de la ligne voulue, capper, mettre dans le SSR
ld a,l : add {combien}+1 : ld l,a ; sauter 1 ligne rapport à la ligne courante et avancer dans notre tableau de définition des lignes
inc h : ld e,(hl) : inc h : ld d,(hl) : ld (#6802),de ; prochaine adresse de rupture programmée
splitLine+={combien} ; mettre à jour notre variable qui tient le compte des lignes
ld a,splitLine : ld (#6801),a : ld (#6800),a ; prochaine INT et rupture à la même ligne
ld de,prochaineInterruption : ld (#39),de ; changer le vecteur pour la prochaine INT
ld h,hi(TABLE_SPLIT) ; adresse de table prête pour la prochaine INT
exx : exa ; re-permuter avant de rendre la main
ei : ret
mend
Cette routine consomme 55 nops soit moins que la durée d'une ligne de temps machine (64 nops). C'est suffisant pour commencer à travailler avec. Comme on va utiliser notre
macro, nous pourrons optimiser à posteriori en ne changeant que le contenu de la macro.
Avant d'utiliser notre macro, nous avons besoin de donner la compensation de départ ainsi que la ligne du premier split (compensation et splitLine).
Enfin, nous aurons aussi besoin de calculer l'adresse de la prochaine interruption. Ici notre code consomme 43 octets, on va choisir de sauter de 64 octets en 64 octets, vous verrez après pourquoi ce choix.
À l'exécution nous aurons besoin d'initialiser une partie des registres secondaires (surtout HL en fait) pour que la routine d'interruption sache quoi lire. Nous pouvons le faire avec une dernière interruption tout en bas de l'écran visible, et surtout démarrer nos interruptions avec cette routine, pour que HL soit initialisé.
Voici le source d'une première démonstration. Vous pouvez télécharger l'ensemble des fichiers nécessaires [ICI]
AXELAY_ROUTINES equ #1000
SPLIT_TABLE equ #3D00 ; table sur la zone #3D00-#3FFF
include 'system.asm' ; RMR/RMR2/UnlockAsic
buildsna
bankset 0
org #100 : run #100
ld sp,#100
RMR ROM_OFF|MODE_0
UnlockAsic (void) ; macro de delock de l'ASIC (system.asm)
RMR2 ASICON ; activer la page de l'ASIC
call preComputeASICinfo ld bc,#BC01 : out (c),c : ld bc,#BD20 : out (c),c ; 32 word width
ld bc,#BC02 : out (c),c : ld bc,#BD00+43 : out (c),c ; centrer à l'horizontale
ld bc,#BC06 : out (c),c : ld bc,#BD20 : out (c),c ; 32 block height
ld bc,#BC07 : out (c),c : ld bc,#BD22 : out (c),c ; centrer à la verticale
ld bc,#BC00+12 : out (c),c : ld bc,#BD20 : out (c),c ; début de l'écran visible en #8000-#BFFF
ld bc,#BC00+13 : out (c),c : ld bc,#BD00 : out (c),c ; poids faible de l'adresse de départ vidéo
ld a,255 : ld (#6800),a ; toute première interruption ligne 255
ld hl,interrupt255 : ld (#39),hl ; vecteur de l'int255
ld a,#C3 : ld (#38),a ; opcode du JP qu'on met en #38
; on attend la VBL pour activer notre palette et lancer les interruptions
; ce n'est PAS grave si l'interruption 255 est exécutée pendant la VBL
; car une interruption était en attente. Tout va bien se passer :)
firstVBL ld b,#F5 : in a,(c) : rra : jr nc,firstVBL
ld hl,lavaPAL : ld de,#6400 : ld bc,32 : ldir
ei
;=============================================
reloop
;=============================================
nop : nop : inc hl : ld a,0 : trigger=$-1 : or a : jr z,reloop : xor a : ld (trigger),a
; la valeur de HL avant de le remettre à zéro nous donnera le temps disponible réel à multiplier par 10
ld hl,0
jr reloop
lavaPAL defw #010,#040,#060,#090,#291,#0B0,#1C1,#0D0,#3D2,#1E1,#3F1,#4F2,#6F3,#9F3,#CF4,#FF7
interrupt255
exx : exa
ld a,21 : ld (#6801),a ; SPLT
ld a,21 : ld (#6800),a ; PRI
ld hl,AXELAY_ROUTINES : ld (#39),hl ; first rupture INT
; interrupt registers reset
.offset ld hl,SPLIT_TABLE+1 ; start a little further to avoid refresh data
.offsetPhase ld a,0 : inc a : and 1 : ld (.offsetPhase+1),a : jr nz,.offsetSkip
dec l
ld (.offset+1),hl
.offsetSkip
inc h : ld d,(hl) : inc h : ld e,(hl) : dec h : dec h : ld (#6802),de ; SPLIT ADDR
xor a : ld (#6804),a ; SSR reset pour le haut de l'écran
inc a : ld (trigger),a ; TRIGGER est une variable remise à 1 une fois par frame
exx : exa
ei : ret
preComputeASICinfo
; produire le tableau des adresses prémâchées CRTC/ASIC pour chacune des 256 lignes d'un écran carré de 64 de large
; SSR Block
; CRTC-13
; CRTC-12
ld ix,SPLIT_TABLE ; adresse de nos 3 tables, alignée sur 256 octets
ld hl,#C000 ; adresse de départ de nos données à afficher
ld c,32 ; nous avons 32 blocs de haut (de 8 lignes)
.computeASIClines
ld b,8 ; boucler sur les 8 lignes d'un bloc
.computeASIClinesBlock
push hl
ld a,h
add a
and #70
ld (ix+0),a ; valeur de bloc prémâchée pour le SSR
inc xh
srl h : rr l
ld a,l
ld (ix+0),a ; poids faible de l'adresse CRTC (REG13)
inc xh
; le calcul ci-dessous est compatible avec n'importe quelle adresse mémoire
; on découpe l'adresse pour renseigner les bits 0,1, 4 et 5 de l'équivalent CRTC registre 12
ld l,h
ld a,h
and #3
ld h,a
ld a,l
srl a
and #30
or h
ld (ix+0),a ; équivalent du REG12
ld xh,hi(SPLIT_TABLE) ; revenir sur le poids fort de départ de nos tables
inc xl ; passer à la ligne suivante dans les tables
pop hl
ld de,#800 ; aller à la ligne du dessous dans le bloc
add hl,de
djnz .computeASIClinesBlock
ld de,64-#4000 ; aller à la ligne du dessous en changeant de bloc
add hl,de
dec c ; encore un bloc à traiter?
jr nz,.computeASIClines
ret
; on va commencer à générer des routines à l'adresse qu'on a choisie (ici #1000)
routineAdresse=AXELAY_ROUTINES
; nos routines font un peu plus de quarante octets, il est facile de connaitre l'adresse
; de la suivante
compensation=#20
splitLine=21
macro splitSkip,combien
org routineAdresse : routineAdresse+=64
exx : exa ; permuter les registres AF,BC,DE,HL
ld a,compensation ; compensation de bloc en accord avec la ligne
compensation=compensation-#10*{combien} ; on ajoute autant de compensation qu'on avance
while compensation<0 : compensation+=#80 : wend ; cette boucle corrige la valeur pour qu'elle soit toujours entre #00 et #70
add (hl) : and #70 : ld (#6804),a ; ajouter au bloc de la ligne voulue, capper, mettre dans le SSR
ld a,l : add {combien}+1 : ld l,a ; sauter 1 ligne rapport à la ligne courante et avancer dans notre tableau de définition des lignes
inc h : ld d,(hl) : inc h : ld e,(hl) : ld (#6802),de ; prochaine adresse de rupture programmée
splitLine+={combien} ; mettre à jour notre variable qui tient le compte des lignes
ld a,splitLine : ld (#6801),a : ld (#6800),a ; prochaine INT et rupture à la même ligne
ld de,routineAdresse : ld (#39),de ; changer le vecteur pour la prochaine INT
ld h,hi(SPLIT_TABLE) ; adresse de table prête pour la prochaine INT
exx : exa ; re-permuter avant de rendre la main
ei : ret
mend macro splitDuplicate,combien
org routineAdresse : routineAdresse+=64
exx : exa ; permuter les registres AF,BC,DE,HL
ld a,compensation ; compensation de bloc en accord avec la ligne
compensation=compensation-#10*{combien} ; on ajoute autant de compensation qu'on avance
while compensation<0 : compensation+=#80 : wend ; cette boucle corrige la valeur pour qu'elle soit toujours entre #00 et #70
add (hl) : and #70 : ld (#6804),a ; ajouter au bloc de la ligne voulue, capper, mettre dans le SSR
if {combien}
ld a,l : add {combien}-1 : ld l,a ; revenir 1 ligne rapport à la ligne courante et reculer dans notre tableau de définition des lignes
inc h : ld d,(hl) : inc h : ld e,(hl) : ld (#6802),de ; prochaine adresse de rupture programmée
splitLine+={combien} ; mettre à jour notre variable qui tient le compte des lignes
assert splitLine<254,'trop loin dans les interruptions!',splitLine
ld a,splitLine : ld (#6801),a : ld (#6800),a ; prochaine INT et rupture à la même ligne
ld de,routineAdresse : ld (#39),de ; changer le vecteur pour la prochaine INT
ld h,hi(SPLIT_TABLE) ; adresse de table prête pour la prochaine INT
else
; dernière ligne, plus de split
ld a,255 : ld (#6800),a
ld hl,interrupt255 : ld (#39),hl
endif
exx : exa ; re-permuter avant de rendre la main
ei : ret
mend ; Et voici un rouleau, plus doux qu'un rouleau de démo ou celui d'Axelay, on veut
; garder du temps machine disponible...
splitSkip 2
splitSkip 2
splitSkip 2
splitSkip 2
splitSkip 2
splitSkip 2
splitSkip 2
splitSkip 3
splitSkip 3
splitSkip 3
splitSkip 3
splitSkip 3
splitSkip 4
splitSkip 4
splitSkip 4
splitSkip 4
splitSkip 5
splitSkip 5
splitSkip 5
splitSkip 6
splitSkip 6
splitSkip 7
splitSkip 9
splitSkip 10
splitSkip 13
splitSkip 36
splitDuplicate 13
splitDuplicate 10
splitDuplicate 9
splitDuplicate 7
splitDuplicate 6
splitDuplicate 5
splitDuplicate 5
splitDuplicate 4
splitDuplicate 4
splitDuplicate 4
splitDuplicate 3
splitDuplicate 3
splitDuplicate 3
splitDuplicate 3
splitDuplicate 2
splitDuplicate 2
splitDuplicate 2
; la dernière n'a pas de rupture qui suit!
; grâce au zéro en paramètre, on sait qu'on doit terminer
; On se contente de positionner le SSR et arrêter la tambouille
splitDuplicate 0 ; Enfin, notre texture qui ne bouge pas dans la mémoire vidéo
org #C000
incbin 'lavaFire.bin' Dans le code, la boucle principale qui ne fait presque qu'attendre, incrémente HL tous les 10 nops.
Quand on pose un point d'arrêt sur le reset de HL, on peut lire la valeur #6B2, soit 1714 x 10 = 17140 nops de temps LIBRE!
L'effet Axelay prend 14% de temps machine, ce qui va nous laisser plein de temps pour ajouter un peu tout ce qu'on veut :)
 Je vous mets une petite capture en mouvement et on se retrouve dans [l'article suivant] pour optimiser et agrémenter notre effet. 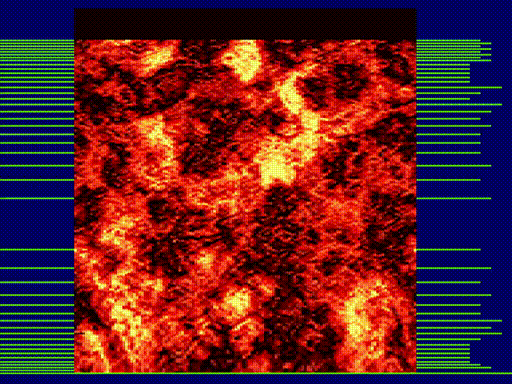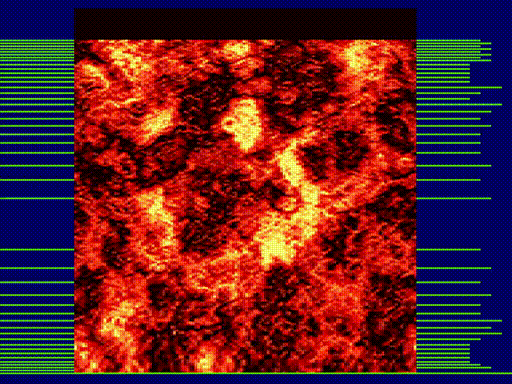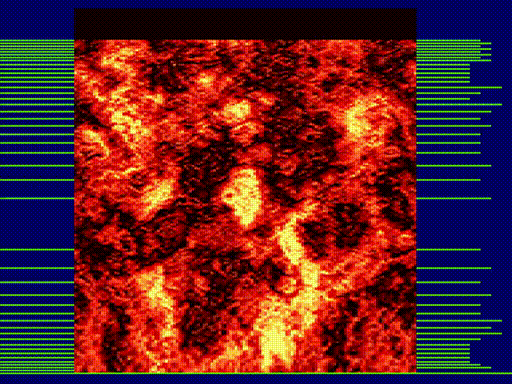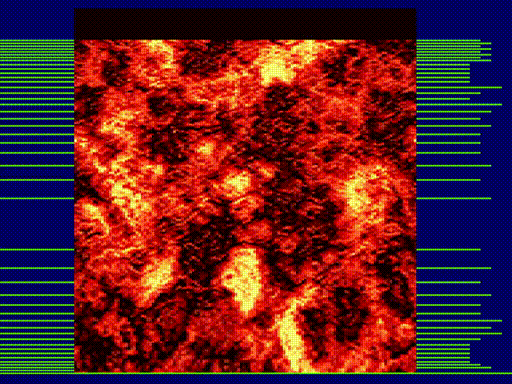
Roudoudou CPCrulez[Content Management System] v8.74-desktop
Page créée en 728 millisecondes et consultée 264 foisL'Amstrad CPC est une machine 8 bits à base d'un Z80 à 4MHz. Le premier de la gamme fut le CPC 464 en 1984, équipé d'un lecteur de cassettes intégré il se plaçait en concurrent du Commodore C64 beaucoup plus compliqué à utiliser et plus cher. Ce fut un réel succès et sorti cette même années le CPC 664 équipé d'un lecteur de disquettes trois pouces intégré. Sa vie fut de courte durée puisqu'en 1985 il fut remplacé par le CPC 6128 qui était plus compact, plus soigné et surtout qui avait 128Ko de RAM au lieu de 64Ko. |
|


{kind=link}