
| ★ CODING ★ CLASSEURS WEKA ★ Comment exploiter toutes les ressources et augmenter les performances de votre AMSTRAD CPC ★ |
| 2/7.1 - Etude générale d'un système à microprocesseur : IV. L'adressage des données - Le décodage | Coding Classeurs Weka |
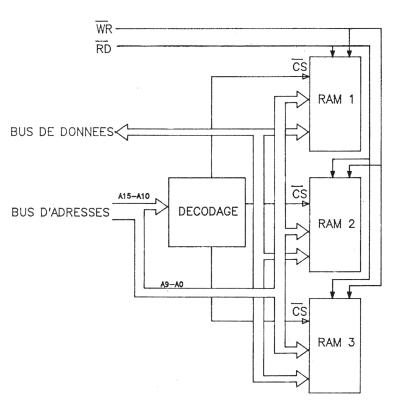
2/7.1 - Etude générale d'un système à microprocesseurIV. L'adressage des données - Le décodage La sélection de boîtier Toutes les données qui seront traitées par un microprocesseur se trouvent, ou se trouveront, dans des composants tels ROM, RAM ou composants d'interfaçage. Lorsque le microprocesseur désirera accéder à une donnée située dans un composant particulier, il ne faut surtout pas que d'autres composants restituent en même temps une des données qu'ils contiennent, de même pour l'écriture, qui doit s'effectuer, généralement dans un seul composant. Pour ce faire, chaque composant possède au moins une broche qui le sélectionne, dénommée selon les cas CS (Chip Select = sélection de boîtier), CE (Chip Enable = validation de boîtier) ou parfois EN (ENable = validation). D'autres composants nécessitent une broche supplémentaire dénommée OE (Output Enable = validation de sortie), comme bien souvent les ROM et les EPROM, qui permet de valider la donnée en sortie du composant. Ainsi, pour lire une donnée située dans un composant d'interfaçage X, il faudra activer ia broche CS de ce composant, et désactiver toutes les broches de validation des boîtiers des autres composants. L'adressage des données - le décodage Rappelons que pour accéder à une donnée, ou la sauvegarder, il faut connaître l'endroit où elle se trouve, c'est-à-dire son adresse. Avec un microprocesseur comportant 16 fils d'adresses, il est possible de réaliser 2 puissance 16 combinaisons différentes sur ces 16 fils, donc 65536 numéros d'adresses différentes (de &0000 à 8FFFF en hexadécimal). A chaque fois qu'il doit manipuler une donnée, le microprocesseur va émettre sur le bus d'adresses le numéro de la case où se trouve la donnée, on appelle cela l'adressage de la donnée. Lorsqu'une adresse est émise, il faut alors qu'un seul composant puisse la fournir. L'adresse fournie doit donc être décodée. Une partie de ce décodage est effectuée par le composant, car il possède des fils d'adresses, mais pas tous. Il faut donc réaliser une autre partie du décodage, en général avec certains, ou tous, fils d'adresses restants, pour sélectionner le boîtier. Prenons pour exemple un boîtier mémoire imaginaire comportant 10 fils d'adresses, un fil de sélection de boîtier, deux broches d'écriture et lecture et un bus de données (voir Fig. 8). Ce boîtier peut adresser de lui-même 2 puissance 10 = 1024 cases internes de huit bits. Avec 65536 cases mémoires possibles pour le Z80, nous pouvons donc placer 65536/1024 = 64 boîtiers mémoires de ce type, autour du microprocesseur. Chaque boîtier devra, par contre, se trouver sélectionner différemment selon l'adresse de la donnée à laquelle on désire accéder. On va donc effectuer un décodage sur les fils d'adresses restants. On pourra décider que le premier boîtier sera ainsi sélectionné lorsque tous les fils d'adresses de A10 à A15 seront à zéro (cette combinaison amenant un zéro sur le CS). Le boîtier numéro 2 sera sélectionné lorsque le fil A10 sera à 1, et les fijs A11 à A15 à zéro (cette combinaison devra amener un zéro sur le CS du deuxième boîtier). De même pour le troisième boîtier avec une combinaison différente et ainsi de suite. Ce décodage sera ainsi effectué grâce à des composants logiques câblés selon une logique dite combinatoire. Après décodage, le premier boîtier mémoire contiendra les données situées aux adresses 000000xxxxxxxxxx — x signifiant n'importe quel état 0 ou 1 — (donc de 0000000000000000 — &0000 — à 0000001111111111 — &03FF). Le deuxième contiendra les données situées aux adresses 000001 xxxxxxxxxx (de 0000010000000000 — &0400 — à 0000011111111111 — &07FF), etc. Supposons maintenant que nous n'ayons besoin que de 3 boîtiers mémoires de ce type.
Dans ce cas, il sera inutile de créer un décodage aussi perfectionné que le précédent, nous utiliserons trois fils d'adresses qui pourront, chacun, être reliés directement sur chaque CS des boîtiers. Ainsi, si l'on a choisi A10, les adresses se situeront entre xxx1 100000000000 (&F800, par exemple, en remplaçant x par 1) et 1111101111111111 (&FBFF) ; les bits A11 et A12 seront placés à 1 pour éviter de sélectionner les autres boîtiers. Pour A11, les adresses seront entre xxxl 010000000000 (&F400) et xxx1011111111111 (&F7FF), ce qui donnera avec A12 les adresses &EC00 à &EF00. Le décodage d'adresses peut ainsi prendre des formes très diverses selon le nombre de boîtiers utilisés et les éventuelles contraintes logicielles.
|