
| ★ CODING ★ CLASSEURS WEKA ★ Comment exploiter toutes les ressources et augmenter les performances de votre AMSTRAD CPC ★ |
| 4/4.5.1 - Optimisation d'écriture dans un fichier texte | Coding Classeurs Weka |
4/4.5 - Utilisation du Turbo-Pascal4/4.5.1 - Optimisation d'écriture dans un fichier texte Il existe essentiellement deux ordres en Turbo-Pascal pour écrire dans un fichier texte. Il s'agit de « Writeln » et de « Write ». (Voir Partie 4, chap. 4.) Le premier ordre sépare les données écrites par un < CR > < LF > (passage à la ligne). Pour des raisons de rapidité de lecture de fichiers texte, il est intéressant d'utiliser la seconde forme d'écriture. Mais alors se pose un problème lorsque l'on veut relire les données écrites. Effectivement, aucun séparateur n'existe entre deux données, et une lecture du type Read (fichier,variable) où variable est une chaîne, qui a toutes les chances de produire une erreur 10 (erreur dans la longueur d'une chaîne) car, une fois lue, cette dernière dépasse les 255 caractères. Une solution pour résoudre ce problème consiste à séparer chaque donnée écrite par un signe séparateur (qui ne fait pas partie des caractères que l'on peut trouver dans le fichier). La lecture d'un tel fichier se fait caractère par caractère avant de rencontrer le séparateur. Nous avons pris le séparateur « / », car il n'apparaît sûrement pas dans les données que vous ou tout autre informaticien manipule tous les jours. Vous pouvez bien sûr changer ce séparateur en effectuant des modifications mineures dans les listings. Ecriture dans un fichier texte en utilisant l'ordre Write Nous donnons comme exemple l'écriture des 300 premiers nombres entiers. Les données sont écrites dans le fichier « g.doc ».
Le contenu du fichier g.doc doit être le suivant après exécution du programme :
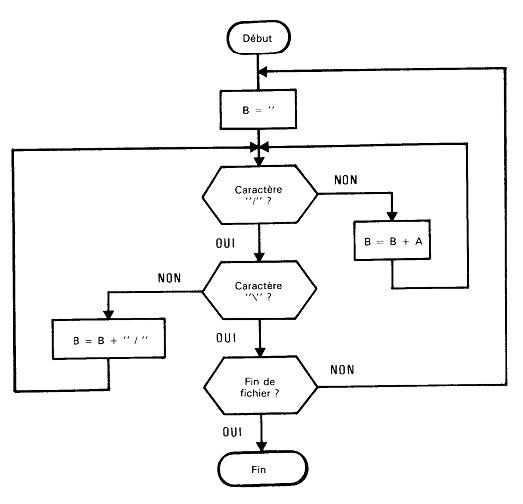
Lecture dans un fichier texte en utilisant l'ordre Write La recherche des deux caractères séparateurs se fait selon l'algorithme suivant. Remarquez que la rencontre du signe slash (/) ne suffit pas pour affirmer qu'un séparateur est rencontré.
L'application de cet algorithme pour retrouver les données enregistrées précédemment dans le fichier « g.doc » donne lieu au programme suivant :
|