
★ APPLICATIONS ★ PROGRAMMATION ★ DATENKOMPRESSION AUF DEM Z80 (CPC AMSTRAD INTERNATIONAL) ★ |
| Datenkompression auf dem Z80 (CPC Amstrad International) | Applications Programmation |
Alles beim alten? Leerdisketten — das leidige Thema heim CPC und PCW Wer keine hat, dringend eine braucht, bekommt keine, weil der nächste Laden mit dieser kostbaren Ware im Angebot lockere 100 km oder weiter entfernt ist* Platz schaffen heißt die Devise, aber wie? Da ja nicht alle Daten, die sich im Laufe der Zeit auf den Datenträgern angesammelt haben, unbedingt auf Abruf bereitstehen müssen, bietet es sich an, Sie mittels bestimmter Programme zusammenzustauchen und in sogenannte Archivdateien zu kopieren. Einige der gängigsten Programme, die diese Funktionen anbieten, können Sie der Tabelle “Packer und Entpacker im Überblick“ entnehmen. Hierbei handelt es sich größtenteils um Public-Domain-Software, die bei den meisten PCW- und CPC-Händlern sowie auch bei uns bezogen werden kann. Packen, aber wie? Die einfachsten Packprogramme wie KOMP und DEKOMP (siehe CPC 10/11'90; Für immer und ewig) orientieren sich an gleichen Zeichenfolgen. Das oben genannte Programm faßt lediglich mehrere aufeinanderfolgende, gleiche Bytes in einer Datei zu zwei Byte zusammen. Hierbei gibt das erste Byte die Anzahl der Wiederholungen und das zweite Byte den jeweils wiederholten Wert an. Diese Methode eignet sich jedoch nicht für bereits optimierte COMmando-Programme, sondern zeigt seine Effizienz lediglich bei Texten oder Quellcodes, die der Übersichtlichkeit halber Unmengen an Leerzeichen in sich vereinen. Bei diesen Dateien läßt sich dann auch ein recht gutes Ergebnis erzielen. Die Datei DBASF2MSG.TXT, die zu dem Programmpaket dBaseII gehört, wartete zum Beispiel mit einer Originallänge von 60 799 Byte auf. Nachdem sie nun mit KOMP zusammengestaucht wurde, umfaßte sie lediglich 55 807 Byte, ein Platzgewinn von rund neun Prozent also. Der Filesqeezer SQ.COM jedoch, der einen anderen Algorithmus benutzt, konnte die Datei sogar auf 37 375 Byte packen, was eine Reduzierung von 39 Prozent bedeutet. Ein beachtliches Ergebnis, das sicherlich so mache Diskette überflüssig werden läßt.
Will man nun alle gepackten Dateien einer Diskette in ein Archiv übernehmen, kann das Programm LU dienlich sein. Es Übergibt mehrere Dateien ohne großen Platzverlust in eine Archivdatei, die dann bequem auf eine Diskette kopiert werden kann und sicherlich auch in Sachen Übersichtlichkeit weiterhilft. Eine Komplettlösung bietet hier jedoch das Programm ARK, welches neben sehr guten Packergebnissen auch gleich eine Archivfunktion beinhaltet. ARK sollte also zum Favoriten werden. Packverfahren Neben dem schon Vorgestellten gibt es außerhalb der CP/M-Barrieren noch andere, wesentlich wirkungsvollere Methoden der Datenkompression. Für Amiga, Atari ST und MS-DOS-PCs ist solche Software schon so üblich, daß sie im großen ganzen gar nicht mehr erwähnt werden muß. Wir möchten Ihnen die zwei am weitesten verbreiteten Algorithmen des LHArc-Packers vorstellen, der auf mehreren Systemen erfolgreich eingesetzt wird. Als erstes sollte das LZSS (Abwandlung des 1982 vorgestellten Lempel-Ziv-Kompressionsverfahrens) behandelt werden. Hierbei wandern alle Daten, bevor Ihre eigentliche Übertragung stattfindet, zunächst in einen Ringpuffer. Vor dein Abschicken einer Zeichcnkette wird dann überprüft, ob sie bereits im Ringpuffer gespeichert ist. Ist das der Fall, wird nicht die Zeichenkette w'citergcgc-ben, sondern der Abstand nach hinten zur alten Kette und die Anzahl der Zeichen, die verwendet werden können. LZSS sendet also entweder Klartext oder Verweise auf schon gesendete Strings. So würde “Abrakadabra“ als “Abrakad“,7,4 gesendet werden. Eine Überprüfungsroutine müßte lediglich noch bei den Zeichen “7,4“ im Ringpuffer nachsehen, der bisher aufgebaut wurde. Der Ringpuffer enthält die letzten übertragenen Bytes also immmer im Klartext. Eine Verschlüsselung findet erst statt, wenn die Zcichen den Puffer verlassen. So einfach dieses Verfahren auch ist, die Kompressionsrate ist bereits verblüffend. Ein komplizierter Tabellenaufbau mit Hash-Funktioncn wie beim verwandten LZH-Verfahren entfällt. Außerdem ist die Dekompression so simpel, daß sie auch ohne Probleme in einem winzigen Assembler-Programm untergebracht werden kann. Beim LZSS-Verfahren muß auch nicht auf häufig auftauchen-de Wörter geachtet werden. Diese sind mit allergrößter Wahrscheinlichkeit sowieso im Puffer enthalten und werden entsprechend verschlüsselt. Was den Algorithmus sehr stark vereinfacht, ist die Beschränkung auf eine maximale Ersetzungslänge. So kommt cs in normalen Dateien nur äußerst selten vor, daß die Länge eines Strings, der ersetzt wird, größer als 60 Zeichen ist. Diese maximale Anzahl von Zeichen wird bereits in den Ringpuffer geladen, ohne gesendet zu sein. Nun wird überprüft. ob dieser String oder ein möglichst langer Teilstring bereits im Puffer vorhanden ist. Wenn ein gefundener Teilstring eine Länge von mehr als einer minimalen Zahl von Buchstaben hat, wird er ersetzt. Dies geschieht, indem die relative Position zum gerade gesendeten Zeichen und die Länge des Strings in die Datei geschrieben werden. Ist der String nicht durch einen Teilstring aus dem Ringpuffer ersetzbar. wird das Zeichen unverändert weitergegeben.
Damit der Entpacker auch reststellt, ob ein Byte in einer komprimierten Datei nun eine Position-Längen-Kombination aus dem LZSS oder ein echtes ASCII-Zeichen ist. wurde vor jedem Buchstaben —vor jeder Zeichenkombination — ein Bit gesendet, das mitteilte, ob ein Buchstabe oder eine Kombination folgte. Dieses Verfahren sieht bereits perfekt aus, ist es aber nicht. Genau an dieser Stelle setzt der zweite Teil des Kompressors von “LhArc“ an. Anstatt ein Bit zu verwenden, das die Längen kennzeichnet, erweitert Yoshis Datenpresse das ASCII-Alphabet um einige Zeichen. Diese Zeichen werden zur Darstellung der Längen, die von LZSS aus dem Ringpuffer geholt wurden, gebraucht. Wenn minimal drei und maximal 60 Buchstaben ersetzt werden, bedeutet dies 58 zusätzliche Zeichen, von denen jedes eine Länge repräsentiert, die verschlüsselt wird. Da es sehr viel mehr Positionen als Längen im Puffer gibt, wäre es dumm, für jede Position einen eigenen Buchstaben einzusetzen. Huffman läßt grüßen Das Huffman-Coding ist eines der ältesten Verfahren zur Datenkompression. Bereits 1952 stellte D.A. Huffman ein brauchbares Verfahren vor, mit dem sich Dateien komprimieren lassen. Das Verfahren von Huffman beruht auf der Idee, daß bestimmte Zeichen im Text sehr viel häufiger erscheinen als andere. In einem Pascal-Quelltext beispielsweise gibt es sehr viel mehr Leerzeichen als etwa "ß". Werden nun nicht alle Zeichen mit Bitfolgen der gleichen Länge übersetzt, sondern durch verschieden lange Bitkombinationen, so daß häufige Zeichen durch kurze Folgen und seltene Zeichen durch entsprechend längere Folgen A=000 B=001 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Packer | Autor | Format(Pateiendung) | Packer | Länge | Datei | |
| ARKV0.1 | Brian E.Moore | ARC | Original | 28671 | BASIC.COM | |
| KOMP 2.1 | Andreas Feldner/DMV | KOM | ARK | 28030 | BASIC.ARK | |
| LU 2.11 | Gary P.Novosielski | LBR | KOMP | 28159 | BASIC. KOM | |
| SQ 1.5 | ?Q? | SQ | 26240 | BASIC.CQM | ||
| Original | 25600 | DMON.BAS | ||||
| Entpacker | Autor | Format(Dateiendung) | ARK | 15480 | DMON.ARK | |
| DEKOMP | Andreas Feldner/DMV | KOM | KOMP | 24063 | DMON.KOM | |
| DELBR v1.1 | Aztec | LBR | SQ | 19320 | DMON.BQS | |
| UNARC 1.6 | Robert A. Freed | ARC | Original | 21370 | JT2.INC | |
| USQ 1.19 | Dave Rand | ?q? | ARK | 8960 | JT2.ARK | |
| KOMP | 18687 | JT2.KOM | ||||
| SQ | 13440 | JT2.IQC | ||||
| Packer tuid Entpacker im Überblick | Die Testergebnisse bei drei verschiedenen Dateiarten | |||||
Warum wählt man also nicht ein Alphabet, das für häufige Buchstaben kürzere. für seltenere Buchstaben dagegen längere Folgen verwendet? Ein solches Alphabet könnte so aussehen:
 “ABRAKADABRA“ wird in diesem Alphabet zu “01011101101011000101110“ und ist damit um neun Bit kürzer als bei der Darstellung mit dem festen Alphabet. Die Decodierung gestaltet sich jedoch geringfügig schwieriger. Die Zeichen müssen nacheinander entschlüsselt werden, da die Position des fünften Buchstabens ebensogut beim sechsten Bit wie beim 18. liegen kann, je nachdem, welche Buchstaben vorangegangen sind. Schwierig ist vor allem die Konstruktion eines solchen Alphabets. Zwei Bedingungen müssen nämlich erfüllt sein:
“ABRAKADABRA“ wird in diesem Alphabet zu “01011101101011000101110“ und ist damit um neun Bit kürzer als bei der Darstellung mit dem festen Alphabet. Die Decodierung gestaltet sich jedoch geringfügig schwieriger. Die Zeichen müssen nacheinander entschlüsselt werden, da die Position des fünften Buchstabens ebensogut beim sechsten Bit wie beim 18. liegen kann, je nachdem, welche Buchstaben vorangegangen sind. Schwierig ist vor allem die Konstruktion eines solchen Alphabets. Zwei Bedingungen müssen nämlich erfüllt sein:
Nichts geht ohne Bäume
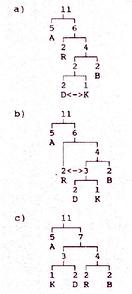 Beide Bedingungen erfüllt der Huffman-Tree. Um ein entsprechendes Alphabet für einen Text optimal zu entwickeln. stellt man das gesamte Alphabet als einen Binärbaum dar.
Beide Bedingungen erfüllt der Huffman-Tree. Um ein entsprechendes Alphabet für einen Text optimal zu entwickeln. stellt man das gesamte Alphabet als einen Binärbaum dar.
Aufbau eines Huffman-Trees: Liste mit Buchstaben und Häufigkeit >>
Die Abbildung “Aufbau eines Huftmann-Trees“ zeigt den zugehörigen Baum für das oben aufgelistete Mini-Alphabet mit festen Längen. Jeder linke Ast in diesem Baum wird mit einer Null versehen, jeder rechte mit einer Eins. Wenn eine Bitfolge decodiert werden soll, wird die Folge als Wegbeschreibung verwendet. Bei einer Null wird der linke, bei einer Eins der rechte Ast weiter untersucht. Sobald auf diesem Wege ein "Blatt“ gefunden wird, ist der Buchstabe decodiert. Der Weg beginnt wieder bei der Wurzel.
<< Adaptive Huffman Coding
Bei einem Alphabet mit variabler Codelänge ist der Baum nun mehr oder weniger “entartet“; er besitzt kurze und lange Äste. An einem solchen Baum können Sie auch sofort erkennen, daß die Bitfolgen eindeutig entschlüsselbar sind: Jeder Weg führt zu genau einem “Blatt“, der Buchstabe ist eindeutig wieder auffindbar. Hier wird auch die Schwäche der Codierungen mit festen Längen offenbar: Manche “Blätter“ sind unbesetzt, die Kombinationen dafür sind nicht definiert. Bleibt also noch das optimale Alphabet, das die Buchstaben möglichst kurz werden läßt. Hierfür erdachte Huffman einen Algorithmus, der für einen bestimmten Text das optimale Alphabet entwirft.
Neben der Herstellung eines optimalen Alphabets ist eine weitere Eigenschaft des Huffman-Trees die “silbing proper-ty“ Betrachten Sie einmal nicht nur die Häufigkeit der Blätter, sondern auch die der Knoten. Gehen Sie nun im Baum zeilenweise von links nach rechts, und klettern Sie mit den Zeilen von unten nach oben. Sie werden feststellen. daß die Häufigkeiten monoton steigend sind, also nie kleiner werden. Diese “silbing property“ ist nicht bloß eine zufällige Eigenschaft aller Huffman-Trees. Es gilt sogar die Regel, daß jeder Baum mit dieser Eigenschaft automatisch ein Huffman-Tree ist. Daher läßt sich die "silbing property" zur Konstruktion von Huffman-Trees benutzen. Dies geschieht im “Adaptive Huffman Coding“, bei dem die Häufigkeiten der jeweils gesendeten Blätter während des Codier-/Decodiervorgangs ständig verändert werden und der Baum an diese Änderungen angepaßt werden muß.
Bei dem Versuch, das Huffman-Verfahren auf Dateien anzuwenden, ergibt sich eine Schwierigkeit: Die Häufigkeit der Buchstaben muß bekannt sein, bevor die Datei entschlüsselt werden kann. Sonst läßt sich der Baum nicht decodieren. Sender und Empfänger müssen genau den gleichen Tree verwenden. Um diese Synchronisation zu erreichen, werden normalerweise zwei “Krücken“ eingesetzt:
1. “Static Huffman Coding“: Der Baum wird nicht für die jeweilige Datei aufgebaut, sondern ist schon vorher vorhanden. Das ist vorteilhaft, wenn viele Dateien gleichen Typs übertragen werden, die ohnehin eine sehr ähnliche Häufigkeitsverteilung haben.
2. “Dynamic Huffman Coding“: Der Baum wird vor der eigentlichen Datei abgespeichert. Ein Verfahren, das sich nur lohnt, wenn die Datei sehr groß ist; die gepackte Datei wird dadurch länger. Um die Probleme der beiden Verfahren zu umgehen, schlug R. Gallager 1978 eine Mischung aus den beiden älteren Algorithmen vor, die zu adaptiven Huffmann-Trees führt. Der Baum ist zunächst wie beim Static-Coding unabhängig von der Datei fest definiert, wird aber nach jedem übertragenen Zeichen angepaßt.
Nach jedem Zeichen nimmt in dem Baum die Häufigkeit dieses Zeichens um eins zu. Nun muß lediglich der so umgewichtete Baum auf die veränderte Situation angepaßt werden. Eine sehr zeitraubende Methode bestünde darin,
den Baum jedesmal wieder neu aufzubauen. Das ist aber überhaupt nicht notwendig, da sich der alte Baum vom neuen jeweils nur minimal unterscheidet. Der Trick liegt hier bei der “silbing property“: Der Baum wird so verändert, daß er dieser Eigenschaft genügt, er ist dann wieder ein Huffman-Tree. Die Anpassung geschieht schrittweise. Zunächst bekommt nur der Knoten, von dem das Blatt ausgeht, die neue Häufigkeit. Dann wird sofort überprüft, ob in diesem Fall die silbing property“ noch gegeben ist. Ist das nicht der Fall — hat also der Knoten eine größere Häufigkeit als seine “rechten“ Nachbarn —, dann wird der Knoten einfach mit dem am weitesten “rechts“ liegenden vertauscht, der eine geringere Wahrscheinlichkeit hat, als der gerade untersuchte Knoten. Die Äste wandern selbstverständlich mit den Knoten mit.
Da der Knoten, der gerade an die Stelle des aktuellen Knotens gelangt ist, die gleiche Wahrscheinlichkeit hat wie der aktuelle Knoten vorher, muß der Zweig nicht weiter angepaßt werden. Wichtig ist nur, die weiteren “Vaterknoten“ in Ihren Häufigkeiten anzupassen und gegebenenfalls wieder zu verschieben. Ein nützlicher Nebeneffekt dieses Verfahrens liegt darin, daß sich der Baum zusätzlich an lokale Häufigkeitsverteilungen von Zeichen anpassen läßt. Eine solche lokale Anpassungsfähigkeit ist wünschenswert, da verschiedene Zeichen auch in einer Datei nicht immer gleichmäßig verteilt Vorkommen, sondern an manchen Stellen gehäuft. Die Anpassung wird erreicht, indem nach einer bestimmten Zeit einfach alle Blatt-Häufigkeiten halbiert werden. Bei einem solchen Schnitt muß allerdings der Baum vollständig neu aufgebaut werden. Durch die Halbierung spielen dann Zeichen, die vor einer bestimmten Zeit aufgetreten sind, eine sehr viel geringere Rolle als neu aufgetretene Zeichen.
Durch das “Adaptive Huffman Coding“ werden nicht nur die LZSS“ Längen -buchstaben“ optimal abgespeichert, sondern auch Buchstaben, die häufiger auftauchen, perfekt komprimiert. Gerade bei Quelltexten von Programmen ist der Wirkungsgrad dieser Kompression offensichtlich: Nicht nur alle Wörter werden beim zweiten Auftreten komprimiert, sondern auch alle Zeichen, die bisher nicht “erwischt“ wurden. Das Semikolon zum Beispiel sitzt mit Sicherheit an einem sehr kurzen Ast und wird dadurch zusätzlich komprimiert. Für unsere Leser, die Freude am Programmieren haben, ist im Heft das Listing eines Komprimierprogramms nach dem Dynamic-Huffman-Coding-Verfahren abgedruckt. Aus Gründen der Geschwindigkeit und der Programmgröße haben wir dafür die Programmiersprache C gewählt. Als Compiler verwendeten wir den Small C-Compiler aus der Public Domain, der auch über den DMV-Verlag erhältlich ist.
|  |
|